publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- CVPR
 OneHOI: Unifying Human-Object Interaction Generation and EditingIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
OneHOI: Unifying Human-Object Interaction Generation and EditingIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026@inproceedings{hoe2026onehoi, title = {OneHOI: Unifying Human-Object Interaction Generation and Editing}, author = {Hoe, Jiun Tian and Hu, Weipeng and Jiang, Xudong and Tan, Yap-Peng and Chan, Chee Seng}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2026}, } - Inf. Fusion
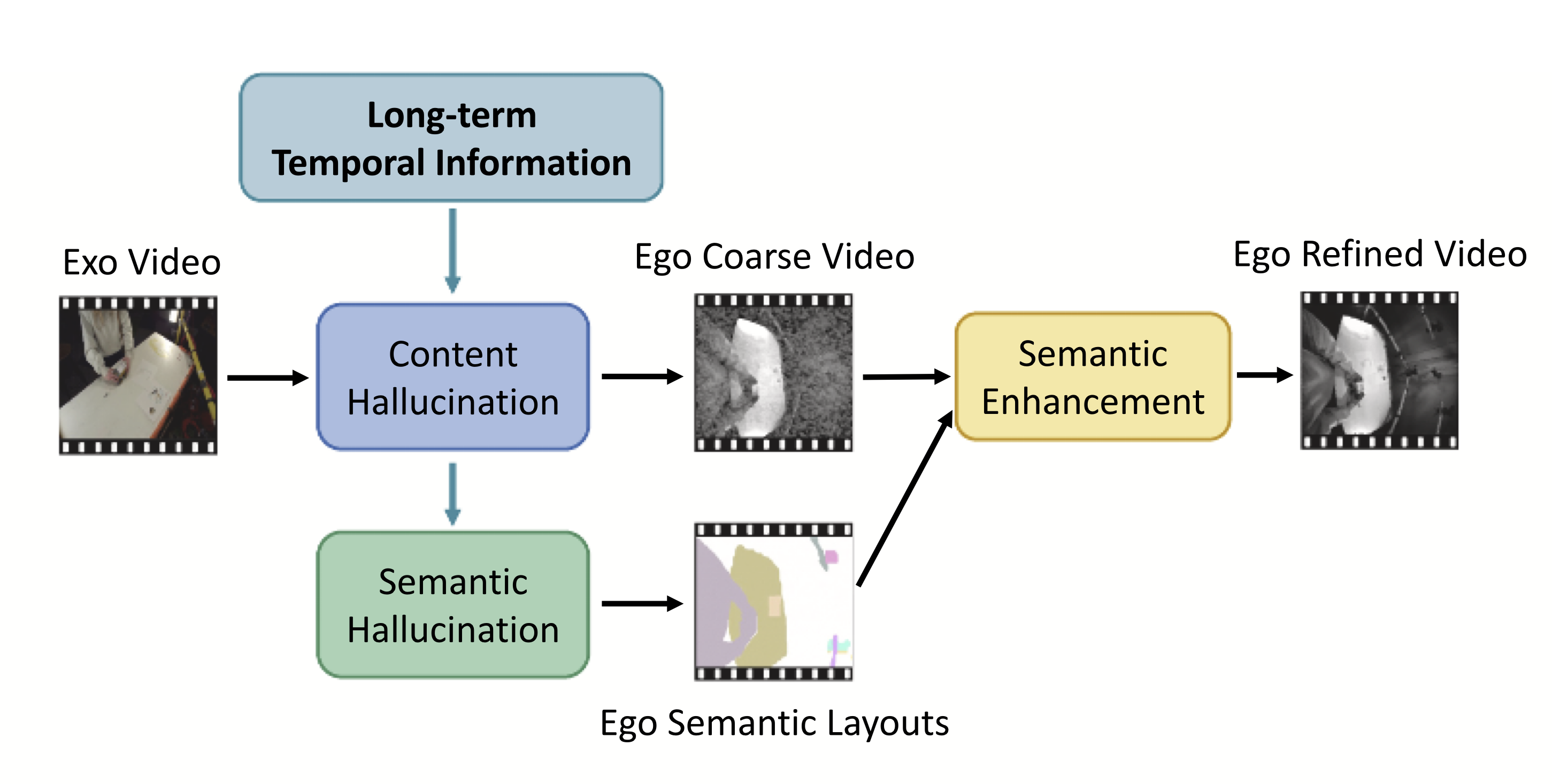 Progressive temporal compensation and semantic enhancement for Exo-to-Ego video generationXingyue Wang, Weipeng Hu, Jiun Tian Hoe, and 3 more authorsInformation Fusion, 2026
Progressive temporal compensation and semantic enhancement for Exo-to-Ego video generationXingyue Wang, Weipeng Hu, Jiun Tian Hoe, and 3 more authorsInformation Fusion, 2026Transforming video perspectives from exocentric (third-person) to egocentric (first-person) is challenging due to limited overlap between two perspectives. Existing approaches often neglect the temporal dynamics-critical for capturing motion cues and reappearing objects-and do not fully exploit source-view inferred semantics. To address these limitations, we propose a Progressive Temporal Compensation and Semantic Enhancement (PCSE) framework for Exocentric-to-Egocentric Video Generation. The Progressive Temporal Compensation (PTC) module focuses on long-term temporal dependencies, progressively aligning exocentric temporal patterns with egocentric representations. By employing a reliance-shifting mechanism with a progression mask, PTC gradually reduces dependence on egocentric supervision, enabling more robust target-view learning. Moreover, to leverage high-level scene context, we introduce a Hierarchical Dual-channel Transformer (HDT), which jointly generates egocentric frames and their corresponding semantic layouts via dual encoder-decoder architectures with hierarchically processed transformer blocks. To further enhance structural coherence and semantic consistency, the generated semantic layouts guide frame refinement through an Uncertainty-aware Semantic Enhancement (USE) module. USE dynamically estimates uncertainty masks to locate and refine ambiguous regions, yielding more coherent and visually accurate results. Extensive experiments demonstrate that PCSE achieves leading performance among cue-free methods.
@article{WangPCSE2026, title = {Progressive temporal compensation and semantic enhancement for Exo-to-Ego video generation}, journal = {Information Fusion}, volume = {130}, pages = {104117}, year = {2026}, issn = {1566-2535}, doi = {https://doi.org/10.1016/j.inffus.2025.104117}, url = {https://www.sciencedirect.com/science/article/pii/S1566253525011790}, author = {Wang, Xingyue and Hu, Weipeng and Hoe, Jiun Tian and Li, Jianhui and Hu, Ping and Tan, Yap-Peng}, keywords = {Cross-view video generation, Exocentric to egocentric synthesis, Progressive compensation, Uncertainty-aware refinement} }
2025
- Neurocomputing
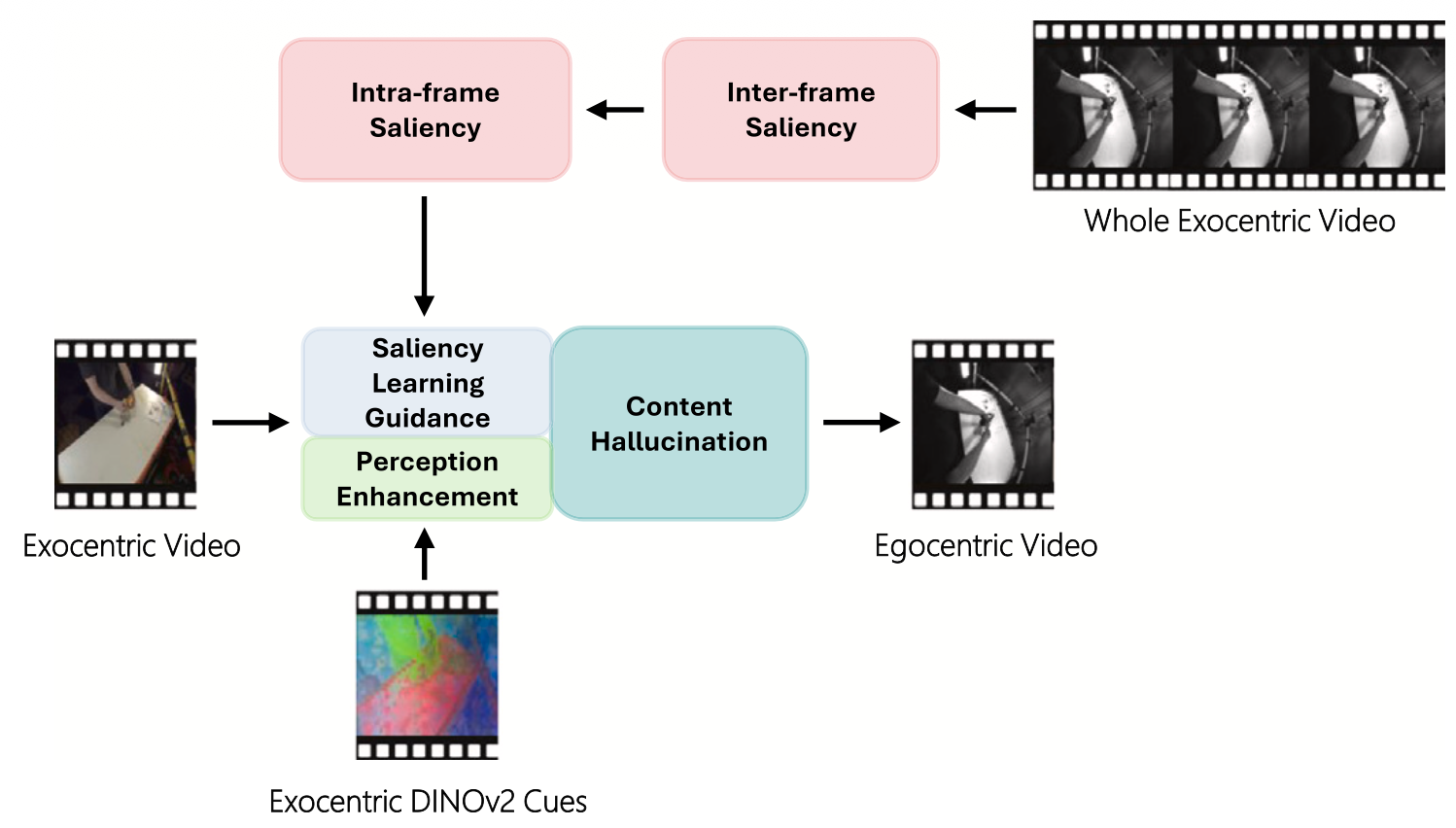 Adaptive memory refinement and perception enhancement for exo-to-ego video generationJianhui Li, Weipeng Hu, Xingyue Wang, and 4 more authorsNeurocomputing, 2025
Adaptive memory refinement and perception enhancement for exo-to-ego video generationJianhui Li, Weipeng Hu, Xingyue Wang, and 4 more authorsNeurocomputing, 2025The task of synthesizing cross-view videos from an exocentric (third-person) to an egocentric (first-person) perspective, referred to as the E2VG problem, remains highly challenging. This is due to the significant viewpoint differences and limited spatial overlap between the two perspectives. Current approaches often fail to capture the temporal dynamics essential for target-view synthesis, and insufficiently leverage source-view perceptual features. In this paper, we present a video-based framework, Adaptive Memory Refinement and Perception Enhancement (ARPE), to address the problem. To capture long-horizon dependencies beyond redundant short-term dynamics, we propose a Distant Temporal Dependencies (DTD) module that extracts egocentric-relevant semantics from temporally distant exocentric frames. By leveraging a sliding window, DTD aligns long-range temporal patterns across views and refines exocentric features through an egocentric-memory guidance. To enhance the focus of the model on informative content, we propose a Saliency-guided Relevance Weighting (SRW) module that adaptively highlights semantically relevant frames and spatial regions. Specifically, SRW assigns inter-frame attention to distant frames based on their relevance to the target-view reconstruction, and further applies intra-frame weighting to emphasize salient areas within each selected frame. These weights are guided by the similarity between the temporal dynamics of the two views, ensuring spatial-temporal consistency. Recognizing the need for semantic consistency across views, we propose the DINOv2 Perception Enhancement (DPE) module. It leverages DINOv2 features to capture view-invariant object-scene cues, thereby improving cross-view feature coherence. Our extensive experimental analysis demonstrates that our approach outperforms existing state-of-the-art methods, excelling in both quantitative metrics and qualitative assessments.
@article{LiARPE2025, title = {Adaptive memory refinement and perception enhancement for exo-to-ego video generation}, journal = {Neurocomputing}, volume = {660}, pages = {131917}, year = {2025}, issn = {0925-2312}, doi = {https://doi.org/10.1016/j.neucom.2025.131917}, url = {https://www.sciencedirect.com/science/article/pii/S0925231225025895}, author = {Li, Jianhui and Hu, Weipeng and Wang, Xingyue and Hoe, Jiun Tian and Hu, Ping and Jiang, Xudong and Tan, Yap-Peng}, keywords = {Cross-view video generation, Exocentric to egocentric synthesis, Adaptive refinement, Perception enhancement} } - TPAMI
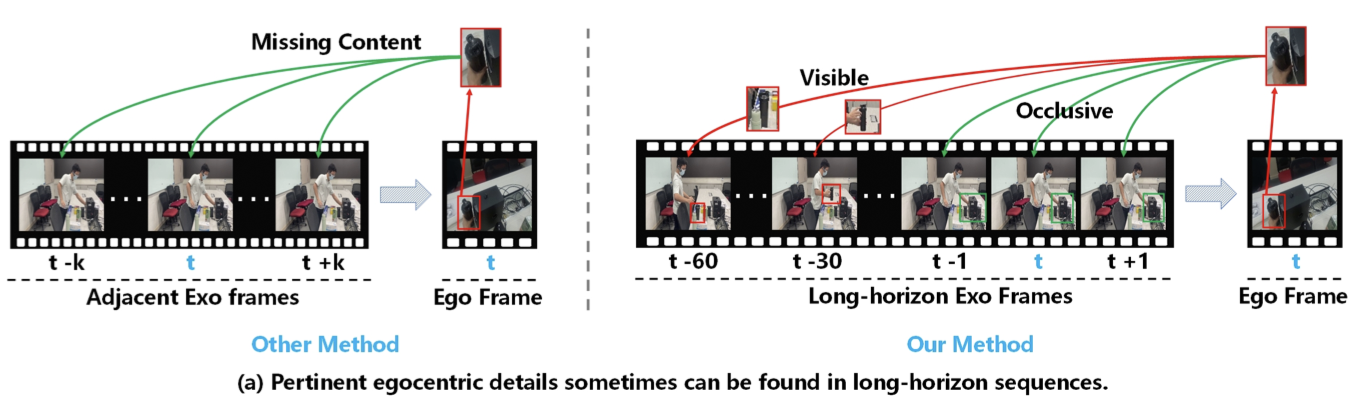 Cascaded Dynamic Memory Refinement and Semantic Alignment for Exo-to-Ego Cross-view Video GenerationWeipeng Hu, Jiun Tian Hoe, Jianhui Li, and 3 more authorsIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Cascaded Dynamic Memory Refinement and Semantic Alignment for Exo-to-Ego Cross-view Video GenerationWeipeng Hu, Jiun Tian Hoe, Jianhui Li, and 3 more authorsIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025@article{hu2025cascaded, title = {Cascaded Dynamic Memory Refinement and Semantic Alignment for Exo-to-Ego Cross-view Video Generation}, author = {Hu, Weipeng and Hoe, Jiun Tian and Li, Jianhui and Hu, Haifeng and Jiang, Xudong and Tan, Yap-Peng}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)}, year = {2025}, publisher = {IEEE} } - Inf. Fusion
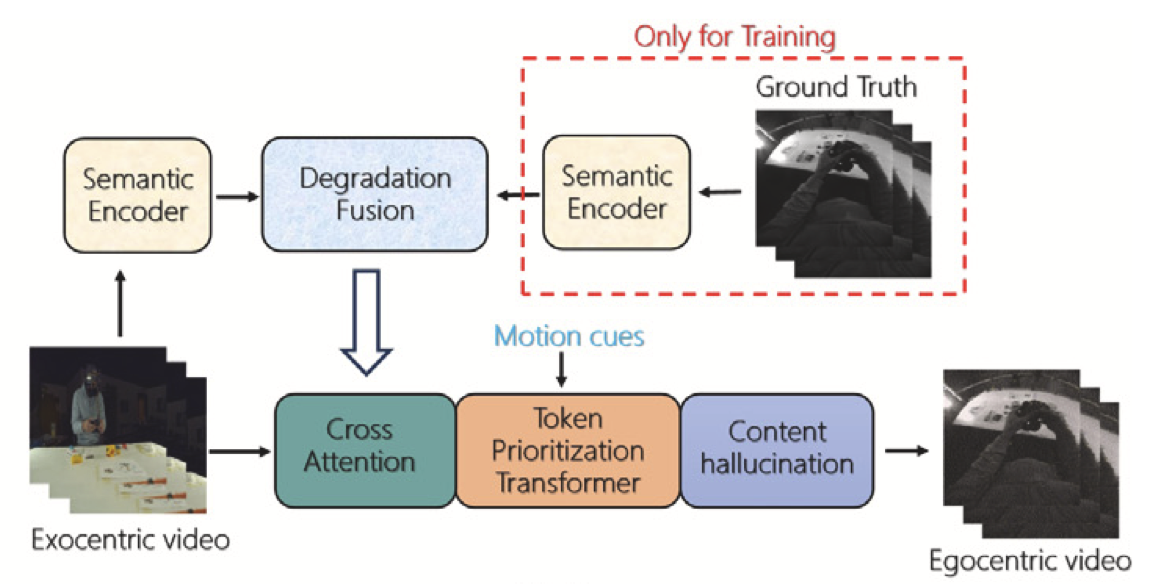 Motion-guided token prioritization and semantic degradation fusion for exo-to-ego cross-view video generationWeipeng Hu, Jiun Tian Hoe, Runzhong Zhang, and 3 more authorsInformation Fusion, 2025
Motion-guided token prioritization and semantic degradation fusion for exo-to-ego cross-view video generationWeipeng Hu, Jiun Tian Hoe, Runzhong Zhang, and 3 more authorsInformation Fusion, 2025@article{hu2025motion, title = {Motion-guided token prioritization and semantic degradation fusion for exo-to-ego cross-view video generation}, author = {Hu, Weipeng and Hoe, Jiun Tian and Zhang, Runzhong and Yang, Yiming and Hu, Haifeng and Tan, Yap-Peng}, journal = {Information Fusion}, pages = {103273}, year = {2025}, publisher = {Elsevier} }
2024
- CVPR
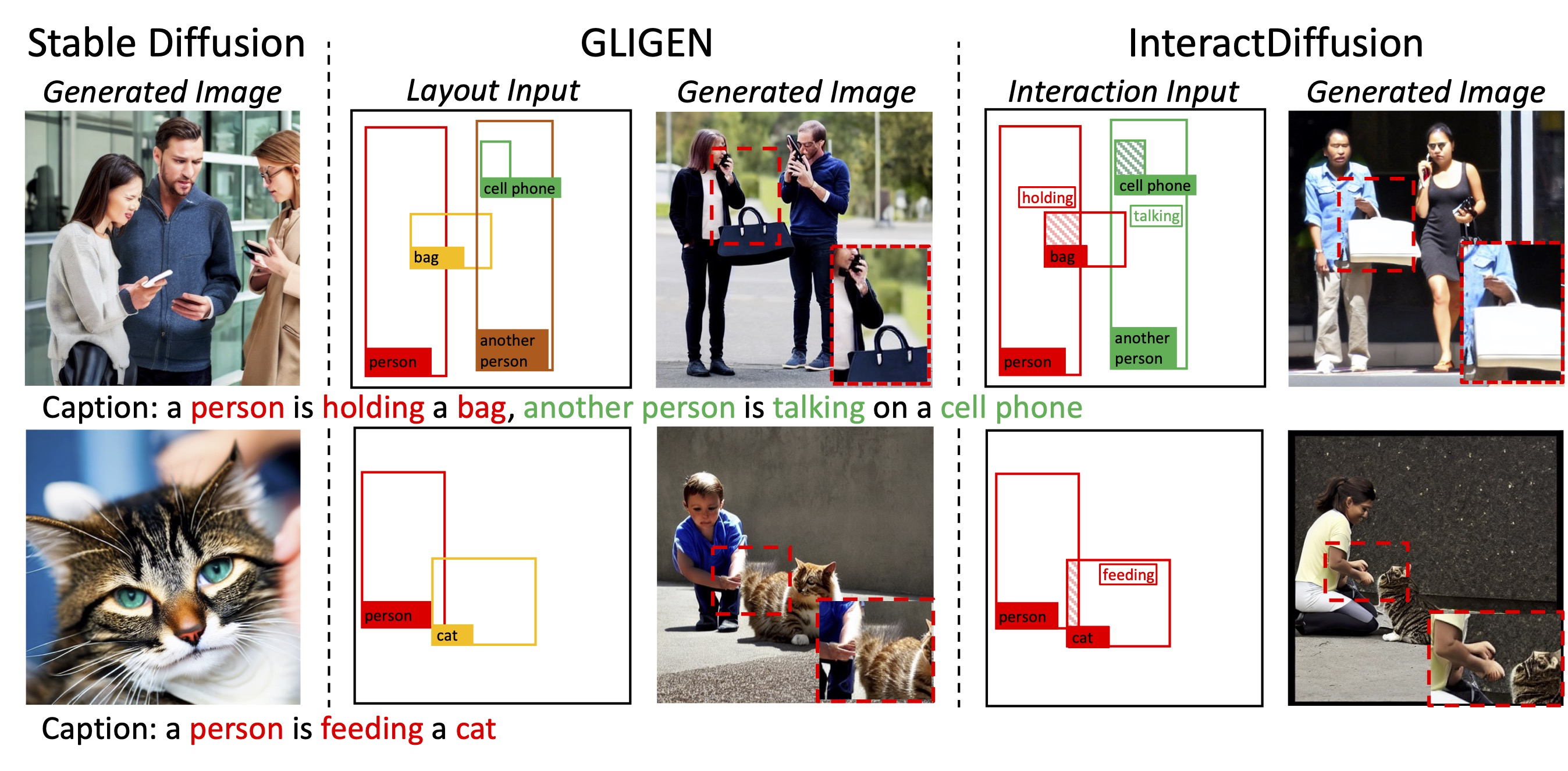 InteractDiffusion: Interaction Control in Text-to-Image Diffusion ModelsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
InteractDiffusion: Interaction Control in Text-to-Image Diffusion ModelsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024@inproceedings{interactdiffusion2024, title = {InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models}, author = {Hoe, Jiun Tian and Jiang, Xudong and Chan, Chee Seng and Tan, Yap-Peng and Hu, Weipeng}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, abs = {Large-scale text-to-image (T2I) diffusion models have showcased incredible capabilities in generating coherent images based on textual descriptions, enabling vast applications in content generation. While recent advancements have introduced control over factors such as object localization, posture, and image contours, a crucial gap remains in our ability to control the interactions between objects in the generated content. Well-controlling interactions in generated images could yield meaningful applications, such as creating realistic scenes with interacting characters. In this work, we study the problems of conditioning T2I diffusion models with Human-Object Interaction (HOI) information, consisting of a triplet label (person, action, object) and corresponding bounding boxes. We propose a pluggable interaction control model, called InteractDiffusion that extends existing pre-trained T2I diffusion models to enable them being better conditioned on interactions. Specifically, we tokenize the HOI information and learn their relationships via interaction embeddings. A conditioning self-attention layer is trained to map HOI tokens to visual tokens, thereby conditioning the visual tokens better in existing T2I diffusion models. Our model attains the ability to control the interaction and location on existing T2I diffusion models, which outperforms existing baselines by a large margin in HOI detection score, as well as fidelity in FID and KID. Project page: https://jiuntian.github.io/interactdiffusion.}, url = {https://arxiv.org/pdf/2312.05849.pdf}, } - TIP
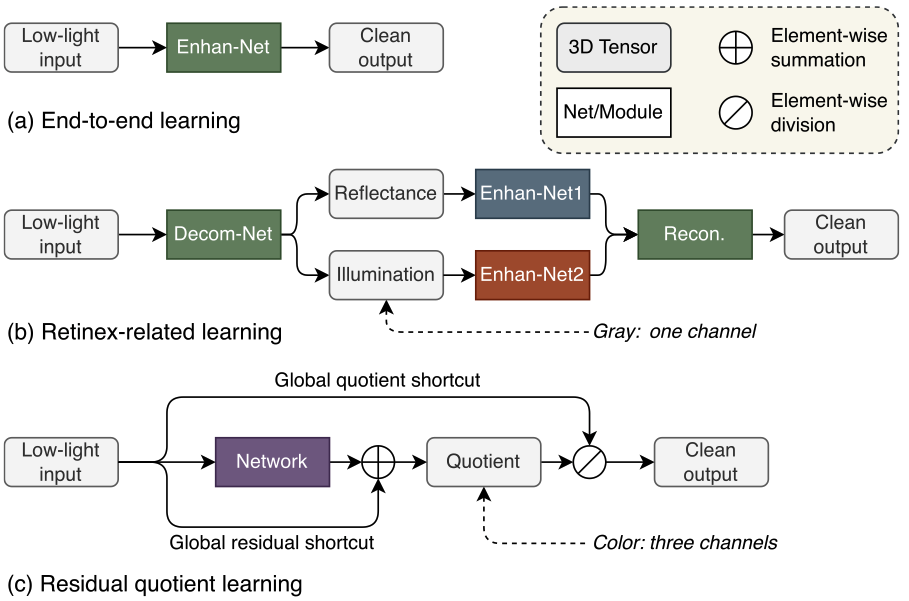 Residual Quotient Learning for Zero-Reference Low-Light Image EnhancementChao Xie, Linfeng Fei, Huanjie Tao, and 5 more authorsIEEE Transactions on Image Processing, 2024
Residual Quotient Learning for Zero-Reference Low-Light Image EnhancementChao Xie, Linfeng Fei, Huanjie Tao, and 5 more authorsIEEE Transactions on Image Processing, 2024@article{xie2024residual, title = {Residual Quotient Learning for Zero-Reference Low-Light Image Enhancement}, author = {Xie, Chao and Fei, Linfeng and Tao, Huanjie and Hu, Yaocong and Zhou, Wei and Hoe, Jiun Tian and Hu, Weipeng and Tan, Yap-Peng}, journal = {IEEE Transactions on Image Processing}, year = {2024}, publisher = {IEEE}, }
2023
- BMVC
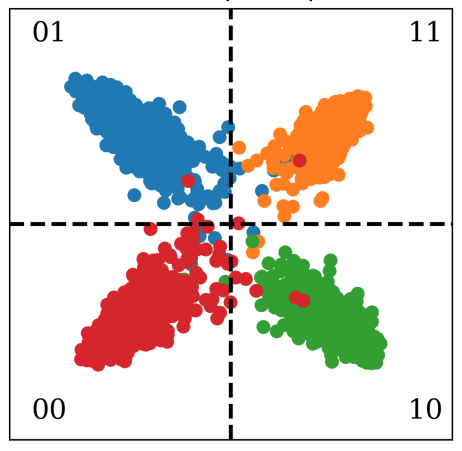 Unsupervised Hashing with Similarity Distribution CalibrationKam Woh Ng, Xiatian Zhu, Jiun Tian Hoe, and 4 more authorsIn British Machine Vision Conference (BMVC) (Oral), 2023
Unsupervised Hashing with Similarity Distribution CalibrationKam Woh Ng, Xiatian Zhu, Jiun Tian Hoe, and 4 more authorsIn British Machine Vision Conference (BMVC) (Oral), 2023@inproceedings{sdc2023, title = {Unsupervised Hashing with Similarity Distribution Calibration}, author = {Ng, Kam Woh and Zhu, Xiatian and Hoe, Jiun Tian and Chan, Chee Seng and Zhang, Tianyu and Song, Yi-Zhe and Xiang, Tao}, booktitle = {British Machine Vision Conference (BMVC) (Oral)}, year = {2023}, abs = {Unsupervised hashing methods typically aim to preserve the similarity between data points in a feature space by mapping them to binary hash codes. However, these methods often overlook the fact that the similarity between data points in the continuous feature space may not be preserved in the discrete hash code space, due to the limited similarity range of hash codes. The similarity range is bounded by the code length and can lead to a problem known as similarity collapse. That is, the positive and negative pairs of data points become less distinguishable from each other in the hash space. To alleviate this problem, in this paper a novel Similarity Distribution Calibration (SDC) method is introduced. SDC aligns the hash code similarity distribution towards a calibration distribution (e.g., beta distribution) with sufficient spread across the entire similarity range, thus alleviating the similarity collapse problem. Extensive experiments show that our SDC outperforms significantly the state-of-the-art alternatives on coarse category-level and instance-level image retrieval. Code is available at https://github.com/kamwoh/sdc.}, url = {https://arxiv.org/pdf/2302.07669.pdf}, }
2021
- NeurIPS
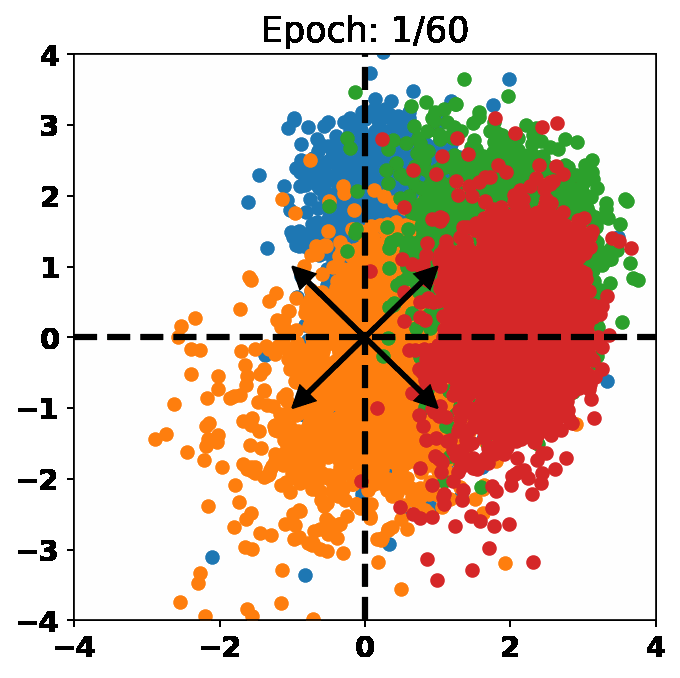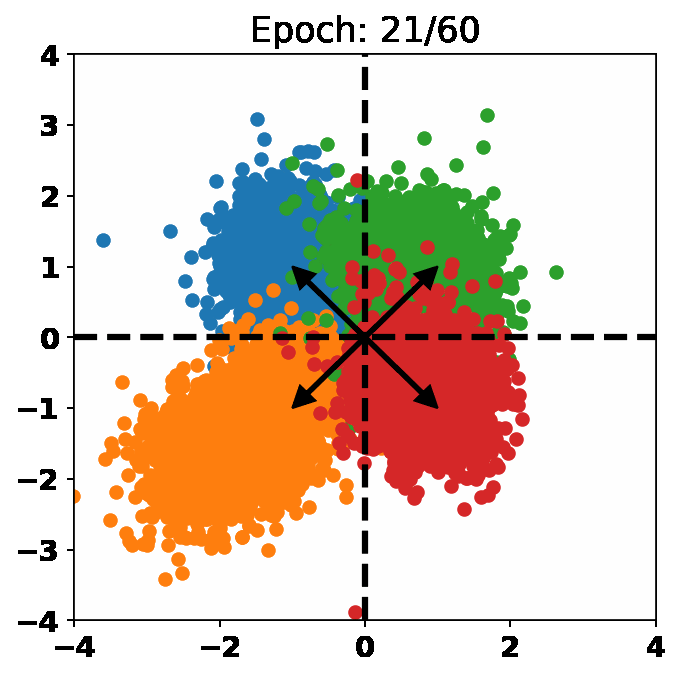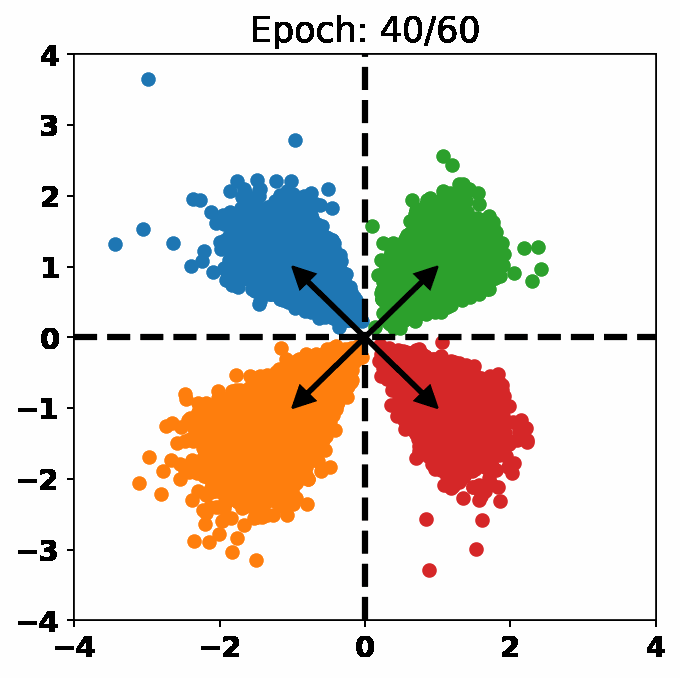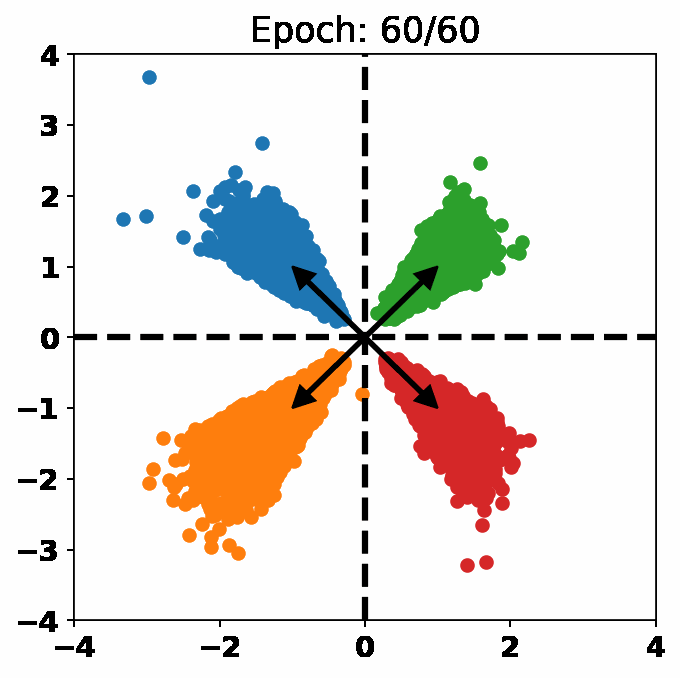 One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning ObjectiveJiun Tian Hoe, Kam Woh Ng, Tianyu Zhang, and 3 more authorsIn Advances in Neural Information Processing Systems (NeurIPS), 2021
One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning ObjectiveJiun Tian Hoe, Kam Woh Ng, Tianyu Zhang, and 3 more authorsIn Advances in Neural Information Processing Systems (NeurIPS), 2021@inproceedings{orthohash2021, title = {One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning Objective}, author = {Hoe, Jiun Tian and Ng, Kam Woh and Zhang, Tianyu and Chan, Chee Seng and Song, Yi-Zhe and Xiang, Tao}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2021}, abs = {A deep hashing model typically has two main learning objectives: to make the learned binary hash codes discriminative and to minimize a quantization error. With further constraints such as bit balance and code orthogonality, it is not uncommon for existing models to employ a large number (>4) of losses. This leads to difficulties in model training and subsequently impedes their effectiveness. In this work, we propose a novel deep hashing model with only . Specifically, we show that maximizing the cosine similarity between the continuous codes and their corresponding can ensure both hash code discriminativeness and quantization error minimization. Further, with this learning objective, code balancing can be achieved by simply using a Batch Normalization (BN) layer and multi-label classification is also straightforward with label smoothing. The result is a one-loss deep hashing model that removes all the hassles of tuning the weights of various losses. Importantly, extensive experiments show that our model is highly effective, outperforming the state-of-the-art multi-loss hashing models on three large-scale instance retrieval benchmarks, often by significant margins. }, url = {https://proceedings.neurips.cc/paper/2021/hash/cbcb58ac2e496207586df2854b17995f-Abstract.html}, }